I subscribe to a lot of email newsletters that are very intriguing,
but I don't always read 'em all.
I made Audioverde to turn these emails into podcasts.
add that feed into your podcast player of choice
(except for spotify..no custom RSS for spotify 🥲).
in a few minutes your episode will show up
It's free to use for now, but maybe I'll have a pricing model around it in the future.
Pipeline
Here's how Audioverde converts a raw email into a podcast feed:
📧
🐴
🎵
🎉
✨
🎊
✨
Raw Email
From: [email protected]
To: [email protected]
Subject: Underrated reasons to be thankful IV
Date: Fri, 28 Nov 2025 17:00:53 +0000
List-Unsubscribe: https://dynomight.substack.com/action/disable_email/disable?token=asdf123123
References: [email protected]
X-Mailgun-Sid: ryJhmzI2MilsIm
X-Mailgun-Sending-Ip: 139.102.224.13
<html>
<body>
<div class="container">
<p>That you can apparently learn to meditate your way into a state of profound relaxation...</p>
<img src="https://cdn.substack.com/113355.png" width="1" height="1"/>
<img src="https://cdn.substack.com/224466.png"/>
<p>That as you gaze into <a href="https://example.com">space</a> at night...</p>
<img src="https://cdn.substack.com/778899.png"/>
<p>As ever, I am thankful to you, for being here.</p>
<div class="footer">
<a href="https://substack.com/efljia">Unsubscribe</a>
</div>
</div>
</body>
</html>
→
Distill
From: [email protected]
To: [email protected]
Subject: Underrated reasons to be thankful IV
Date: Fri, 28 Nov 2025 17:00:53 +0000List-Unsubscribe: https://dynomight.substack.com/action/disable_email/disable?token=asdf123123
References: [email protected]
X-Mailgun-Sid: ryJhmzI2MilsIm
X-Mailgun-Sending-Ip: 139.102.224.13
<html>
<body>
<div class="container">
<p>That you can apparently learn to meditate your way into a state of profound relaxation...</p><img src="https://cdn.substack.com/113355.png" width="1" height="1"/>
<img src="https://cdn.substack.com/224466.png"/><p>That as you gaze into <a href="https://example.com">space</a> at night...</p><img src="https://cdn.substack.com/778899.png"/><p>As ever, I am thankful to you, for being here.</p>
<div class="footer">
<a href="https://substack.com/efljia">Unsubscribe</a>
</div>
</div>
</body>
</html>
→
Simplified Content
From: [email protected]
To: [email protected]
Subject: Underrated reasons to be thankful IV
Date: Fri, 28 Nov 2025 17:00:53 +0000
That you can apparently learn to meditate your way into a state of profound relaxation...
https://cdn.substack.com/113355.png
https://cdn.substack.com/224466.png
That as you gaze into space at night...
https://cdn.substack.com/778899.png
As ever, I am thankful to you, for being here.
→
Filter with LLM
Prompt to gemini-2.5-pro:
Is this suitable for narration?
That you can apparently learn to meditate your way into a state of profound relaxation...
https://cdn.substack.com/113355.png
https://cdn.substack.com/224466.png
That as you gaze into space at night...
https://cdn.substack.com/778899.png
As ever, I am thankful to you, for being here.
Response: ✓ Proceed
→
Extract Figures
https://cdn.substack.com/113355.png
0.5 KB
✗ Discarded (too small - tracking pixel?)
https://cdn.substack.com/224466.png
45 KB
✓ Keep
https://cdn.substack.com/778899.png
38 KB
✓ Keep
→
Describe Figures
https://cdn.substack.com/224466.png
LLM Description: A thanksgiving feast.
https://cdn.substack.com/778899.png
LLM Description: Workers in a field.
→
Generate Script
Prompt to gemini-2.5-pro:
Generate a podcast narration script with an intro and outro:
That you can apparently learn to meditate your way into a state of profound relaxation...
That as you gaze into space at night...
As ever, I am thankful to you, for being here.
Figure descriptions:
- Figure 1: A thanksgiving feast.
- Figure 2: Workers in a field.
→
Narration Script
This is "Underrated reasons to be thankful IV" by dynomight.
That you can apparently learn to meditate your way into a state of profound relaxation...
Now there's an image: A thanksgiving feast. Now back to the article.
That as you gaze into space at night...
Here we see another image: Workers in a field. Back to the text.
As ever, I am thankful to you, for being here.
Thanks for listening. This has been an Audioverde production.
→
Split Long Scripts (if needed)
This is "Underrated reasons to be thankful IV" by dynomight, part one.
That you can apparently learn to meditate your way...
Now there's an image: A thanksgiving feast. Now back to the article.
That was part one of "Underrated reasons to be thankful IV" by dynomight. Find the remaining parts in your podcast feed. Thank you for listening and goodbye.
This is "Underrated reasons to be thankful IV" by dynomight, part two.
That as you gaze into space at night...
Here we see another image: Workers in a field. Back to the text.
As ever, I am thankful to you, for being here.
That was the conclusion of "Underrated reasons to be thankful IV" by dynomight. Thank you for listening and goodbye.
→
Text-to-Speech
Chunk 1 Text → WAV
"This is 'Underrated reasons to be thankful IV' by dynomight, part one."
✓ audio_chunk_1.wav (2.1 sec)
Chunk 2 Text → WAV
"That you can apparently learn to meditate your way..."
✓ audio_chunk_2.wav (3.8 sec)
Chunk 3 Text → WAV
"Now there's an image: A thanksgiving feast. Now back to the article."
✓ audio_chunk_3.wav (4.2 sec)
Chunk 4 Text → WAV
"That as you gaze into space at night..."
✓ audio_chunk_4.wav (3.5 sec)
Chunk 5 Text → WAV
"Here we see another image: Workers in a field. Back to the text..."
✓ audio_chunk_5.wav (5.3 sec)
→
Concatenate
1.wav
2.wav
3.wav
4.wav
5.wav
↓
combined_part_1.wav (18.5 sec)
→
Convert to MP3
combined_part_1.wav
2.1 MB
↓
episode_part_1.mp3
445 KB
→
Serve RSS to Podcast Player
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0">
<channel>
<title>Audioverde - dynomight</title>
<description>Personal podcast feed</description>
<item>
<title>Underrated reasons to be thankful IV (Part 1)</title>
<description>From [email protected]</description>
<pubDate>Fri, 28 Nov 2025 17:00:53 +0000</pubDate>
<enclosure
url="https://r2.audioverde.com/episode_part_1.mp3"
length="445000"
type="audio/mpeg"/>
<guid>audioverde-12345-part1</guid>
</item>
<item>
<title>Underrated reasons to be thankful IV (Part 2)</title>
<description>From [email protected]</description>
<pubDate>Fri, 28 Nov 2025 17:00:53 +0000</pubDate>
<enclosure
url="https://r2.audioverde.com/episode_part_2.mp3"
length="412000"
type="audio/mpeg"/>
<guid>audioverde-12345-part2</guid>
</item>
</channel>
</rss>
Technical
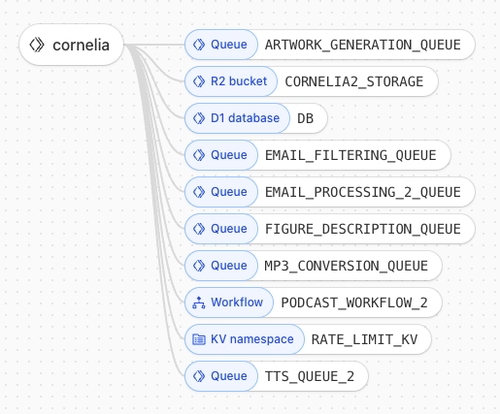
I started with a Cloudflare worker and expanded into using a variety of Cloudflare services:
their queues, R2 (artifact storage), D1 (sql), KV (kv):
Cloudflare is a fun platform -- very nice in terms of Typescript support,
APIs, docs, really clean deploy process (under 10s for the whole thing),
their CLI tool wrangler and their GUIs are nice too.
I jumped through some hoops (noted below) to keep everything in their env and I'm glad it worked out.
In other projects (like FHAI)
I had to migrate part of the backend away from Cloudflare
and onto a more "traditional" backend server environment (in that case Google Cloud Run).
I'm glad I didn't have to do that here!
Some details on the more interesting steps in the pipeline:
Filtering
Early on the in the workflow I send distilled content to an LLM
(right now gemini-2.5-pro)
and my simple prompt asks if the content is suitable for podcast narration.
My thinking is that I should rule out spam
since anyone could trigger my workflow by firing a message to [email protected]
, and I don't want that.
The whole workflow will terminate if this filtering step decides that the email is not suitable.
This could still cost me pennies for processing a high amount of spam,
but I figure if that starts to happen I can block the incoming mail upstream of this,
perhaps based on sender characteristics.
This and subsequent LLM calls go into their own queue.
I like the Cloudflare queues
because it makes it clear how to manage timeouts/retries for these calls.
Right now I'm not self hosting any LLMs, I'm generally using high end models through APIs.
Those API calls would fail with error 524
(esp before I started streaming responses back)
because the LLM might think for a while and the API might return nothing for several minutes, and Cloudflare would terminate the connection.
So the queues help manage retries in those cases.
Cloudflare will also spin up more consumer workers if the queue is getting backed up.
Artwork
I thought it would be fun if everyone's unique podcast had customized cover art.
So this artwork gets generated for new users on their first use of the workflow.
I start with a green background image
(credit to Rebecca Orlov | Epic Playdate
on Unsplash)
and use SVG to add text on top.
For now the custom part is just the sender's email address.
Then I use the resvg web assembly module
to convert SVG to PNG and save the result.
The WASM binary is added directly in src.
I think this pattern of using WASM opens up some cool things that could be done on Cloudflare Worker isolates,
even in their somewhat restricted environment.
There is also an offline step that converts fonts to SVG paths, but I manage that in a one-off way.
Figures
Some incoming emails have visual elements, "figures."
I download these and then an LLM (again gemini-2.5-pro) describes them.
If it's a tracking pixel or some UI icon I just discard that.
To help in the description, I give the LLM the text that surrounds the figure
and I ask it to say something novel and try not to repeat the surrounding text.
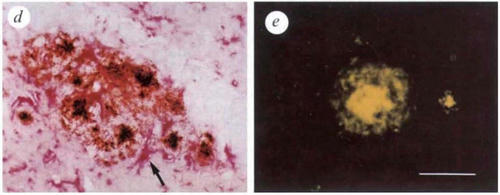
This image displays two micrographs of amyloid plaques.
The left panel (d) is a light micrograph of a multicentric plaque with dense cores,
while the right panel (e) shows a single plaque glowing yellow under fluorescence microscopy.
Narration Script
The crux of the whole operation is to create a script for the TTS engine to narrate.
I prompt an LLM to create this script using the raw email content + figure descriptions.
It's prompted to add the appropriate metadata like title, author and published date,
as well as a coda and various custom [PAUSE] markers throughout.
I had some issues with handling really large emails
(specifically later in the workflow when we're dealing with large WAV files
and bumping up against Cloudflare worker isolate memory limit of 128MB),
and so at this stage we may split the episode into N roughly equal parts based on a character length threshold.
These parts are processed as their own unique episodes with a bit of metadata to link it all together.
TTS
And finally we can generate some audio.
I'm switching between gpt-4o-mini-tts and gemini-2.5-pro/flash-preview-tts.
The gemini models are still in preview and have tighter rate limits.
I found 11Labs too expensive.
The script is broken up into chunks of text and then sent out for TTS,
and again this is mediated by a Cloudflare queue.
The snippets of audio that come back are cached, then eventually glued back together in order.
I inject some silence where the script has [PAUSE] markers.
I add music to the beginning and end.
The full epsisode WAV file is converted to MP3 via lamejs --
I think I tried some WASM stuff here too but ended up going the pure js route.
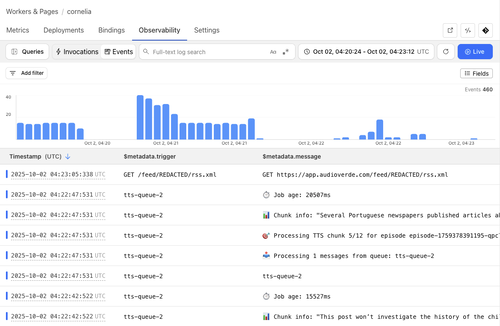
Observability
For now I just use the Cloudflare GUI to look at logs and trace any issues:
I also manually track costs --
I store some metadata about each LLM call in D1 and calculate total costs at the end of the workflow
using the vendor-provided pricing rates.
Most of the costs come from TTS --
for example gpt-4o-mini-tts costs about $0.90 per hour of generated output audio.
Most newsletters are small and processing them costs about $0.10 each.
Overall
This was great fun to build and improve over a few weeks!
I used Cursor (with Sonnet 3.5/3.7) and now mostly Claude Code to work on this project,
it's been great with typescript.
The major challenge has been architecture and managing the eccentricities of the Cloudflare environment --
the codegen tools don't really understand how to navigate that (or perhaps this is just a skill issue wrt prompting?)
Many additional features are possible:
handling attachments,
narrating a long chain of email conversation like a message board,
a separate bookmarklet (are those still a thing??) to send web page content into the pipeline
I'd love for you to give it a try and please tell me what you think:
Fwd your newsletter to [email protected]
and you'll receive a reply with a link to your custom RSS feed.